焼きなまし法と山登り法
先日、Kaggleのコンペに参加しました。もみの木の形をした樹木を敷き詰めるという問題で、入賞者の多くは焼きなまし法を採用していました。
shu10038.weblog.to
私も昔山登り法や焼きなまし法というのを聞いたことがあるのですが、自分で実装したりしたのは初めてでした。なので勉強がてらにこの記事を作成しました。
焼きなまし法とは
最適化問題に取り組んだことのあるならば、一度は「局所最適解」という言葉を耳にしたことがあるかと思います。昔は「ローカルミニマム」という言い方で習った気がします。
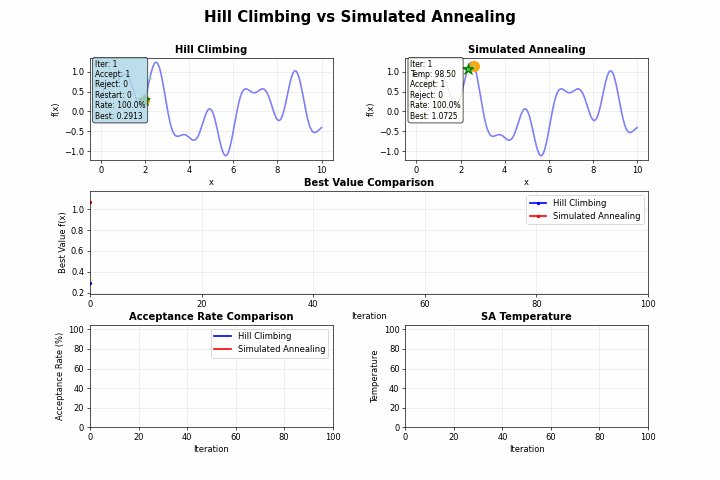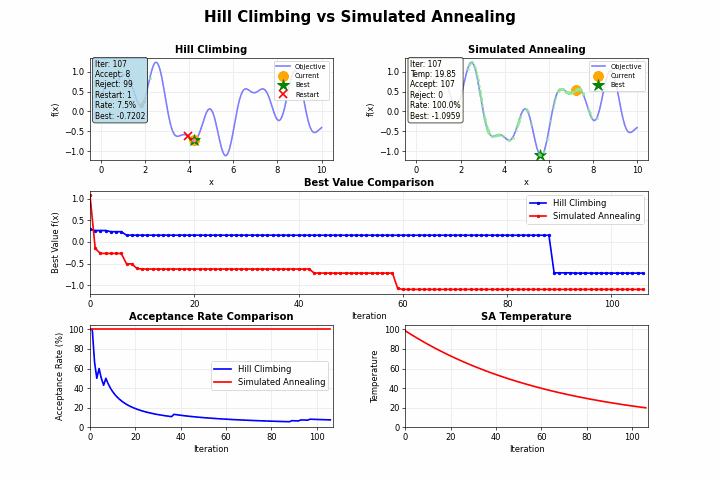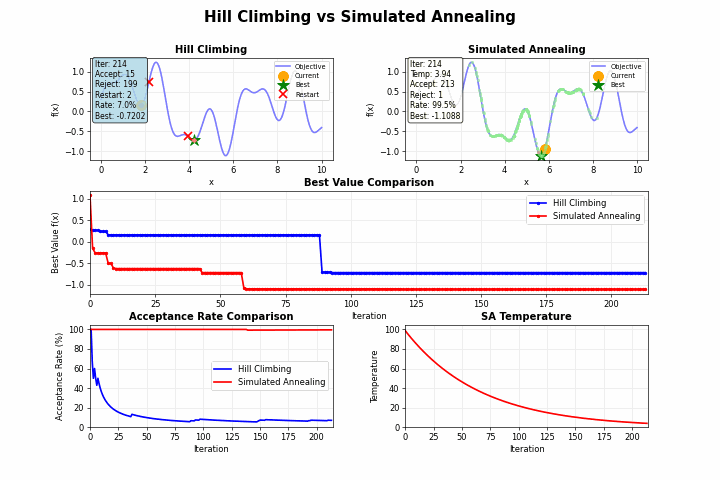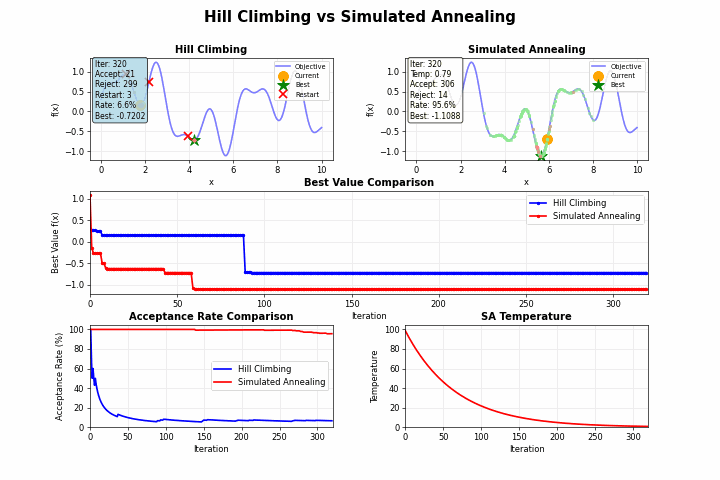
山登り法(Hill Climbing)のような単純な探索アルゴリズムは、目の前の改善のみを追求するあまり、より良い解が他にあるにもかかわらず、早期に探索を終了してしまうことがあります。
しかし、焼きなまし法を用いることで、局所最適解から抜け出すこともあります。金属加工における「焼きなまし(アニーリング)」という工程では、金属を加熱してからゆっくり冷却することで、結晶構造の欠陥を減らし、より安定した状態を得ることができます。この物理現象を模倣したのが「焼きなまし法(Simulated Annealing)」です。
焼きなまし法の核心
焼きなまし法の最も革新的な点は、一時的に悪化する移動も確率的に許容するという点にあります。この許容度を制御するパラメータが「温度」です。
温度の計算は単純で、下記のように指数減衰する関数を用います。
# 受理確率の計算式 def acceptance_probability(delta, temperature): if delta < 0: return 1.0 # 改善する場合は常に受理 else: return math.exp(-delta / temperature) # 悪化する場合は確率的に受理
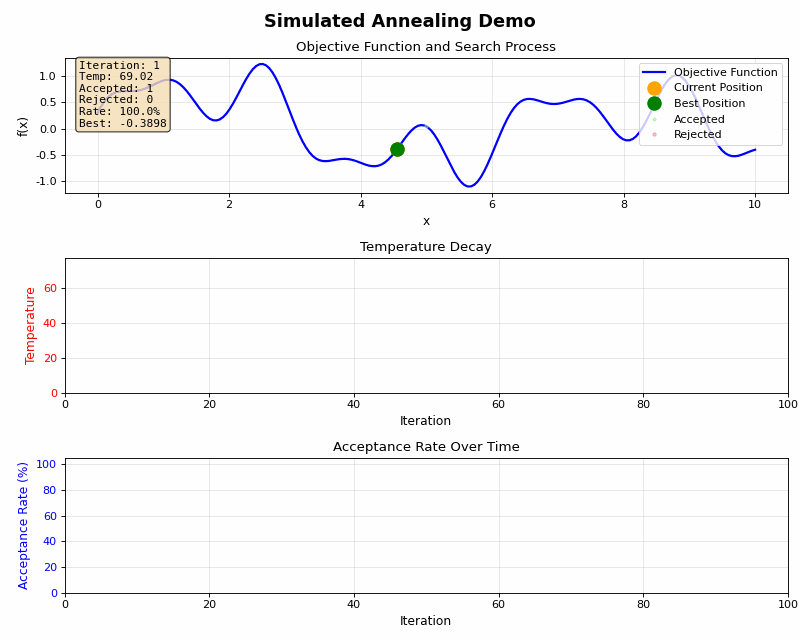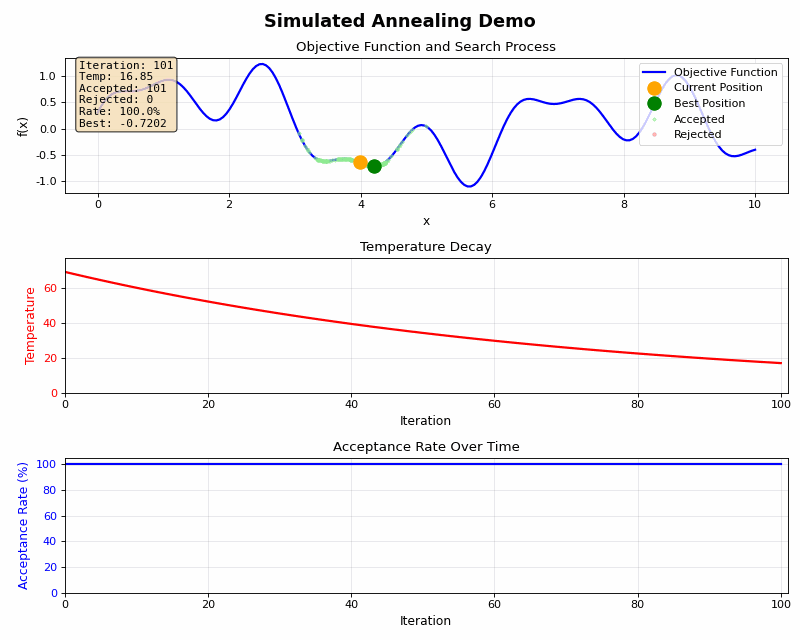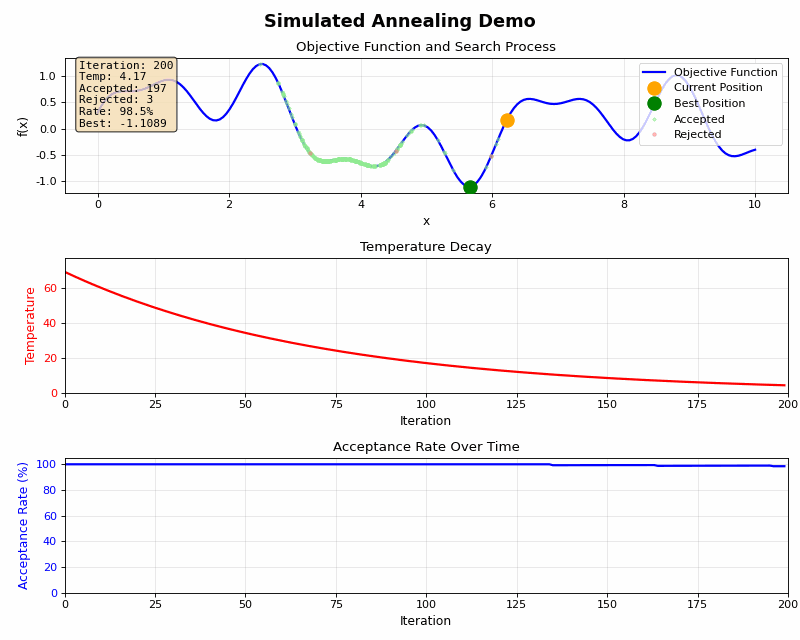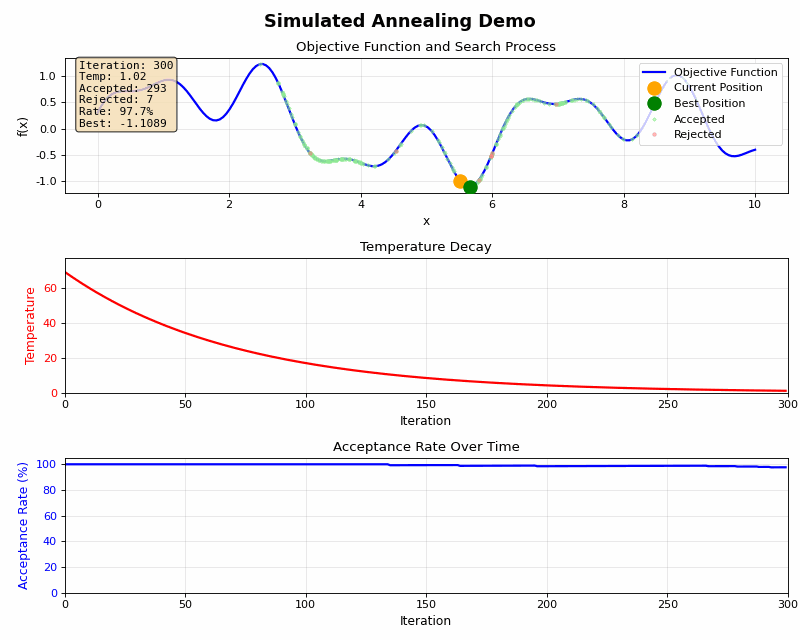
高温時と低温時にはそれぞれ下記のような特徴があります。
高温時(初期段階):
- 温度が高い → exp(-Δ/T) の値が大きい
- 大きな悪化でも高い確率で受理
- 探索モード:広範囲を探索し、局所最適解から脱出
低温時(後期段階):
- 温度が低い → exp(-Δ/T) の値が小さい
- 小さな悪化でもほとんど受理されない
- 活用モード:現在の最適解付近を細かく調整
また温度をゆっくり下げたり、急激に下げたりすることで下記のような特徴があります。
急冷(冷却率が高い):
- 計算時間は短いが、局所最適解に収束するリスクが高い
- 例:冷却率0.9
徐冷(冷却率が低い):
- 大域的最適解を見つける可能性が高いが、計算時間が長い
- 例:冷却率0.99~0.999
温度が可能にするパラダイムシフト
ここで焼きなまし法の真価が発揮されます。高い温度では、「悪化する移動も受け入れる」 ことができます。これが何をもたらすかというと:
「今の整然とした配置を、あえて崩す権利」 です。
# 構造転換のイメージ def structural_change(current_layout): # 高温時:あえて良い配置を崩す if temperature > 50: # 1. 現在:4列に整然と並んでいる # 2. 崩す:あえてランダムに散らす(一時的にスコア悪化) # 3. 再構築:5列に並び替える(最終的にスコア改善) return destroy_and_rebuild(current_layout)
焼きなまし法なし:
■ ■ ■ ■ ← 4列(固定) ■ ■ ■ ■ ■ ■ ■ ■
text
焼きなまし法あり:
初期:■ ■ ■ ■ ← 4列(良いが最適ではない)
高温時:■ ■ ← 一度バラバラに(一時悪化)
■ ■
■ ■
低温時:■ ■ ■ ■ ■ ← 5列に再配置(最終改善)
■ ■ ■ ■ ■
この「一旦崩してから再構築」こそが、焼きなまし法の核心です。
VS CodeでPoetryやuvの仮想環境をアクティベートする
Pythonの仮想環境をVS codeで呼び出してデバッグしようとして色々調べたのでメモをしておきます。
一番簡単と思われる方法
Python環境の設定
VS Codeを開いて
- コマンドパレット(Ctrl + Shift + P)を開いて「Python: Select Interpreter」を検索
- 「Enter interpreter path」 → **「Find…」**を選択
- 下記の仮想環境のパスからbin/python(Windowsの場合はScripts/python.exe)を指定(パスの獲得については下記)
上記で上手く行かない場合
VS codeの左側の拡張一覧からPython Debugger 拡張機能をインストール

(左の拡張一覧からPython Debugger 拡張機能をインストールしないと「Could not find debugpy path」と出る)
launch.jsonの設定
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal"
}
]
}
settings.jsonの作成
.vscode/settings.jsonを下記のように設定。(settings.jsonは無ければ手動で作成)
{
"python.defaultInterpreterPath": "${workspaceFolder}/.venv/Scripts/python.exe",
"python.terminal.activateEnvironment": true,
"python.debugpyPath": "${workspaceFolder}/.venv/Lib/site-packages/debugpy"
}終わったらF1 → Developer: Reload Window
仮想環境の確認
現在の仮想環境やパッケージが正しいか確認するためのスクリプトを実行する方法
import sys import os print(f"Python executable: {sys.executable}") print(f"Python version: {sys.version}") print(f"Environment: {os.getenv('VIRTUAL_ENV')}")
またターミナルから直接確認するには
python -c "import sys; print(sys.executable)"
多くの場合、.venv を有効化するとターミナルのプロンプト(コマンド入力の左側)に
(.venv) $
と表記される。
Pythonの仮想環境ツールuvの基本的な使い方
ちょっと前から使い始めたuv。
まだまだ使い慣れていなくて、ここいらで基本的な使い方を書いておいて、いつでも参照できるようにしておきたいと思います。
新しいプロジェクトの作成
uv init
パッケージの追加
uv add
プロジェクト直下に .venv/ を作成
export VENV_DIR=.venv
(Windows CMD)
set VENV_DIR=.venv
$env:VENV_DIR = ".venv" uv venv
VS Code で仮想環境を .venv に固定するには、.vscode/settings.json に以下を追加:
{
"python.defaultInterpreterPath": ".venv/bin/python"
}
プロジェクトルートで実行
python -m venv .venv
その上で uv を使う
uv pip install .
source .venv/bin/activate
.venv\Scripts\activate
これにより、.venv がプロジェクト内に作られ、VS Code でも自動認識されるようになります(VS Code は .venv があればそれを優先的に使います)
VS Code に .venv を認識させる(オプション)
.vscode/settings.json に以下を記述しておくと、明示的に VS Code に .venv を使わせることができるようです
"python.pythonPath": ".venv/bin/python"
または、最近の VS Code ではこの設定項目は非推奨となりつつあるため、代わりに Python インタープリターをコマンドパレットから選ぶのが推奨されます。
なぜ uv は仮想環境を自動作成しないのか?
現時点(2025年時点)で、uv は Poetry のように .venv を自動的に作成・管理する機能は持っていないらしいです。つまり、uv 自体に poetry config virtualenvs.in-project true のような「仮想環境をプロジェクト直下に作る設定」は 存在しないっぽいです。
uv はあくまで パッケージマネージャー(pip互換) であり、環境管理(仮想環境の作成・管理)はしない設計思想です。つまり
- uv = 高速な pip・pip-tools の代替
- 仮想環境の作成 = python -m venv や他ツールに任せる
という分離設計になっています。
配布パッケージの作成
最近パッケージ化をしていてます。パッケージ化の方法をChatGPTなどのLLMなどで調べたので、流れる前にメモしておきます。
qiita.com
- build は、Python パッケージをビルドするための 高レベルのツール。setup.py に依存せず、pyproject.toml を利用してパッケージをビルド可能との事。
- wheel は、Python パッケージの バイナリ配布フォーマット であり、それを作成するためのツール。
buildを使う方法
最近の Python では build モジュールを使うのが推奨されています。
この方法では pyproject.toml に build-system を定義して python -m build でビルドします。
ビルドツールの準備
まず、必要なツールをインストール。
pip install build
pyproject.toml の準備
pyproject.toml を作成し、setuptools を指定
[build-system] requires = ["setuptools", "wheel"] build-backend = "setuptools.build_meta"
ビルドの実行
プロジェクトのルートディレクトリで
python -m build
すると、dist/ フォルダ内に以下のようなファイルが生成される
dist/ my_pack-0.1.0.tar.gz # ソースディストリビューション(sdist) my_pack-0.1.0-py3-none-any.whl # Wheel(bdist_wheel)
setuptools の setup.py で bdist_wheel を使う方法
pip install setuptools wheel
setup.py を作成:
from setuptools import setup, find_packages
setup(
name="my_pack",
version="0.1.0",
packages=find_packages(),
install_requires=[
"numpy",
"pandas"
],
)
ビルドの実行
python setup.py sdist bdist_wheel
すると、dist/ フォルダ内に .tar.gz(ソース)と .whl(Wheel)が生成される。
この方法の特徴
- setup.py が必須
- pyproject.toml は不要(ただし、併用は可能)
- 古い方法 だが、まだ使われることがある
【メモ】
AWSのCodeCommitの操作
CodeCommitでPushするまで
変更を全てステージングに追加
git add .
特定のファイルだけステージングに追加
git add example.txt
コミット
git commit -m "Add example.txt with a simple message"
PUSH
git push
ステージングを解除
git restore --staged example.txt
Poetryのコマンド
Poetyのコマンドは忘れがちなので、メモしておきます。
仮想環境にPythonをインストール
例えば、Python 3.9.8をインストールする場合。
pyenv install 3.9.8
pyenvを使用して、プロジェクトディレクトリでPython 3.9.8を使用する。
pyenv local 3.9.8
poetryプロジェクトディレクトリで、poetryの仮想環境を再作成。
poetry env use $(pyenv which python)
仮想環境が正しくアクティブになっていることを確認。
poetry shell
仮想環境がアクティブな状態で実行。
python XXXX.py
もしくは
poetry run python XXXX.py
poetry.lock の不整合の解消
poetryのlockファイルにの不整合があると
pyproject.toml changed significantly since poetry.lock was last generated. Run poetry lock [--no-update] to fix the lock file.
というメッセージが出力されるので、以下のコマンドでlockファイルを更新
poetry lock
Poetryプロジェクトを初期化
以下のコマンドを実行して、プロジェクトを初期化。
poetry init
このコマンドを入力すると、対話形式でプロジェクト名、バージョン、依存関係などを設定できる。質問に応じて回答するか、デフォルト設定を使用するべし。
Poetryの仮想環境管理設定 Poetryには仮想環境の管理に関する設定がある
poetry config virtualenvs.in-project true
のように設定している場合、プロジェクトディレクトリ内に.venvフォルダが作成される。
一方、デフォルト設定(poetry config virtualenvs.in-project false もしくは未設定)の場合は、システムの共有ディレクトリ(通常は~/.cache/pypoetry/virtualenvsなど)に仮想環境が作成される。
ただし、プロジェクトディレクトリに書き込み権限がない場合や特定の条件下では、virtualenvs.in-projectを有効にしていても.venvが生成されない場合がある。
環境変数POETRY_VIRTUALENVS_IN_PROJECTを設定することで、.venvの生成挙動を制御できます。この環境変数がtrueに設定されていると、プロジェクトディレクトリ内に仮想環境が作られる。
pandasインストール時のエラー
表題の通り、Pandasを再インストール指定たら、下記のようなエラーが出ました。
AttributeError: partially initialized module 'pandas' has no attribute '_pandas_parser_CAPI' (most likely due to a circular import)
多少難儀したので、解決方法をメモしておきます。
ちなみにエラーが出力されたのはバージョンは2.2.0
解決法
まずpip uninstall pandasでアンインストールしてからpip install pandas==2.1.0で旧バージョンをインストールしたら直りました。